
Publications
Asterisks (“*”) indicate equal contribution.
Please refer to my Google scholar page for the full list.
|
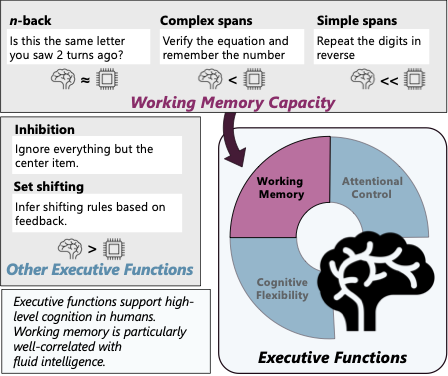
Strong Memory, Weak Control: An Empirical Study of Executive Functioning in LLMsKarin De Langis, Jong Inn Park, Khanh Chi Le, Andreas Schramm, Andrew Elfenbein, Michael C. Mensink, Dongyeop Kang Proceedings of the European Chapter of the Association for Computational Linguistics (EACL), 2026 paper / Assesses LLM comprehension of narrative temporal aspect with an expert-in-the-loop probe pipeline, revealing over-reliance on prototypicality, inconsistent aspect judgments, and weak causal reasoning, and introducing a standardized framework for evaluating cognitive–linguistic capabilities. |
|
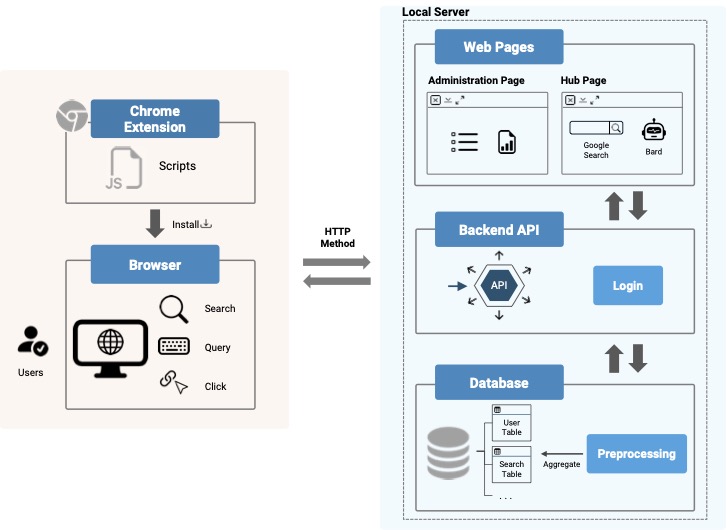
Consumer Engagement With AI-Powered Search Engines: Implications for the Future of Search Advertising Research and PracticeGabriel Garlough-Shah, Jong Inn Park, Shirley Anugrah Hayati, Dongyeop Kang, Jisu Huh Journal of Advertising Research, 2026 paper / This work investigates how consumers engage with AI-powered search engines (AIPSEs) compared to traditional search engines (TSEs), focusing on differences in motivations, choice, and usage behavior. To support this analysis, we developed and deployed a Chrome Extension to collect real-world search interaction data, enabling a detailed comparison of user behavior across search paradigms. This research represents a multi-stage effort—from initial presentation at AEJMC 2024 to publication in the Journal of Advertising Research—highlighting its contribution to understanding the evolving landscape of search and its implications for advertising research and practice. |
|
How LLMs Comprehend Temporal Meaning in Narratives: A Case Study in Cognitive Evaluation of LLMsKarin De Langis, Jong Inn Park, Andreas Schramm, Bin Hu, Khanh Chi Le, Dongyeop Kang Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2025 paper / Assesses LLM comprehension of narrative temporal aspect with an expert-in-the-loop probe pipeline, revealing over-reliance on prototypicality, inconsistent aspect judgments, and weak causal reasoning, and introducing a standardized framework for evaluating cognitive–linguistic capabilities. |
|
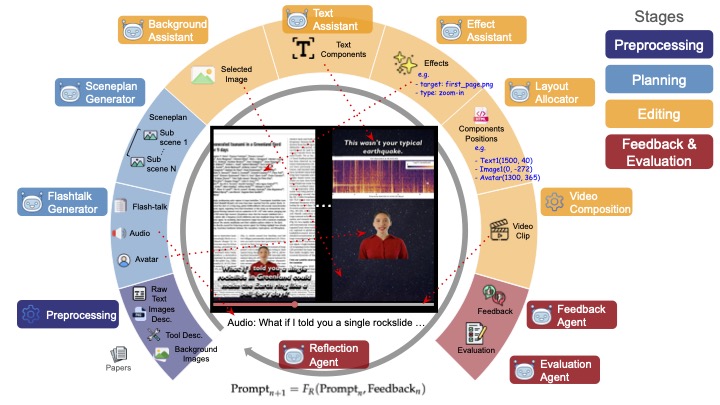
Stealing Creator's Workflow: A Creator-Inspired Agentic Framework with Iterative Feedback Loop for Improved Scientific Short-form GenerationJong Inn Park, Maanas Taneja, Qianwen Wang, Dongyeop Kang arXiv, 2025 arXiv / project page / Proposes SciTalk, a creator-inspired multi-LLM pipeline that grounds short-form science videos in text, figures, and style cues, using specialized agents and iterative feedback to surpass one-shot prompting in factual accuracy and engagement. |
|
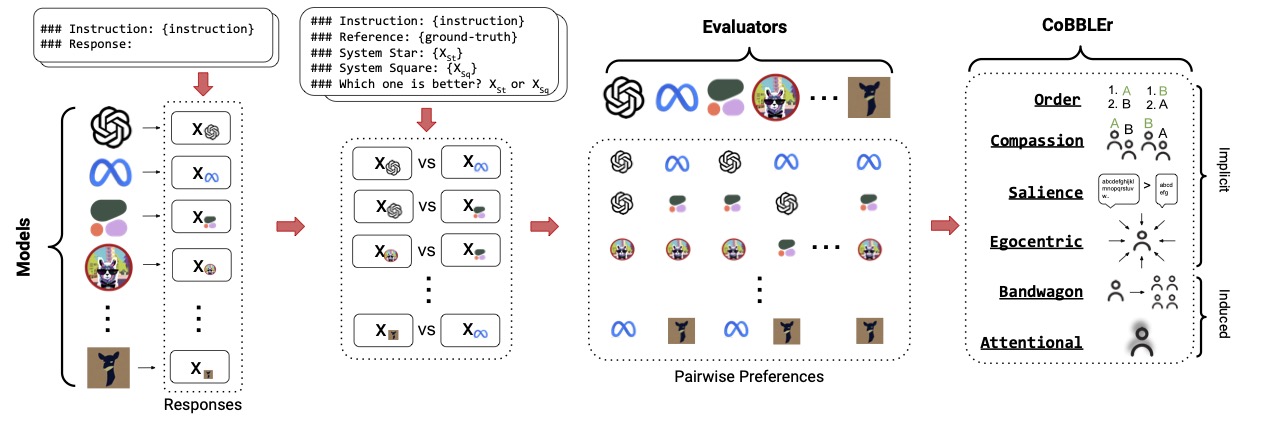
Benchmarking Cognitive Biases in Large Language Models as EvaluatorsRyan Koo, Minhwa Lee, Vipul Raheja, Jong Inn Park, Zae Myung Kim, Dongyeop Kang Findings of the Association for Computational Linguistics (ACL), 2024 arXiv / project page / code / data / Evaluated 16 large language models (LLMs) as automatic evaluators using preference ranking and introduced the Cognitive Bias Benchmark for LLMs as Evaluators (COBBLER), revealing significant cognitive biases and misalignment with human preferences, indicating limitations in using LLMs for automatic annotation. |
|
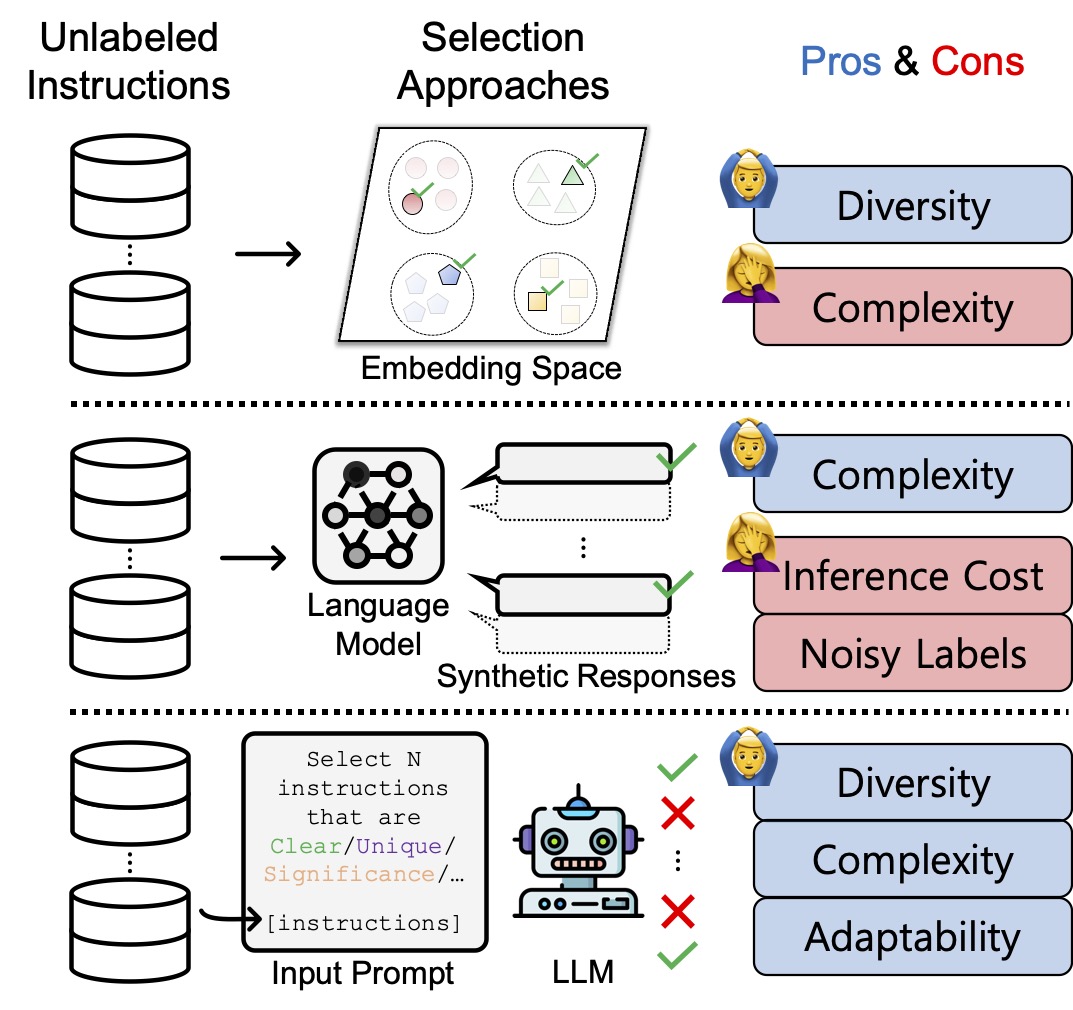
SelectLLM: Can LLMs Select Important Instructions to Annotate?Ritik Sachin Parkar*, Jaehyung Kim*, Jong Inn Park, Dongyeop Kang arXiv, 2024 arXiv / code / Developed SelectLLM, a framework utilizing coreset-based clustering and large language models to enhance the selection of unlabeled instructions for improved instruction tuning performance. |
|
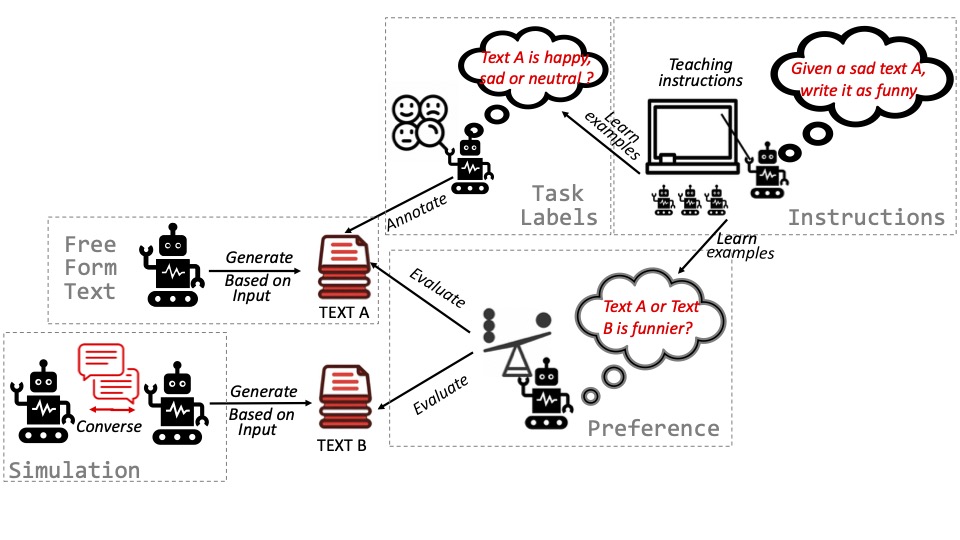
Under the surface: Tracking the artifactuality of llm-generated dataD. Das*, K.D. Langis*, A. Martin*, J. Kim*, M. Lee*, Z.M. Kim*, S. Hayati, R. Owan, B. Hu, R. Parkar, R. Koo, J.I. Park, A. Tyagi, L. Ferland, S. Roy, V. Liu, D. Kang arXiv, 2024 arXiv / project page / code / data / Explored the expanding role of large language models (LLMs) in generating artificial data, analyzing various types of LLM-generated text and their implications, revealing significant disparities compared to human data, especially in complex tasks, and emphasizing the need for ethical practices in data creation and addressing biases. |